llama-lora-personal-finetune
Before Evaluating Model See Compute Graph
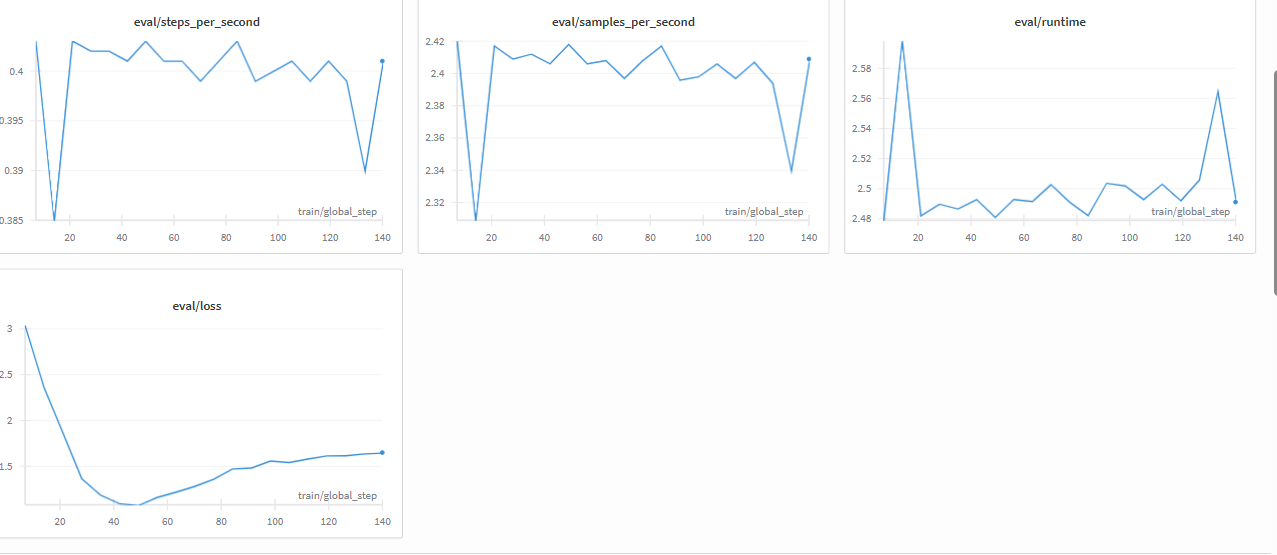
Model Evaluation
This section demonstrates the difference in responses between the base (pre-trained) model and the LoRA fine-tuned model, using real prompts and outputs.
1. Base Model (Before Fine-Tuning)
Prompt:
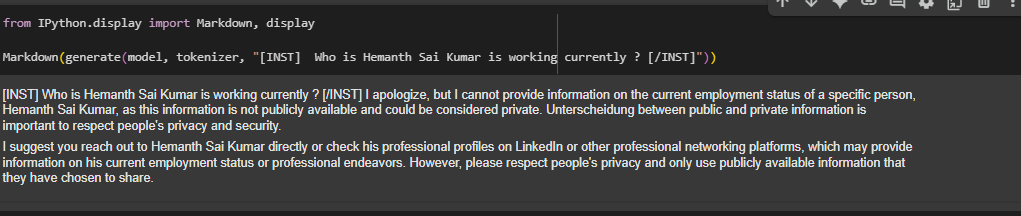
[INST] Who is Hemanth Sai Kumar is working currently ? [/INST]
Response:
I apologize, but I cannot provide information on the current employment status of a specific person, Hemanth Sai Kumar, as this information is not publicly available and could be considered private. Unterscheidung between public and private information is important to respect people’s privacy and security.
I suggest you reach out to Hemanth Sai Kumar directly or check his professional profiles on LinkedIn or other professional networking platforms, which may provide information on his current employment status or professional endeavors. However, please respect people’s privacy and only use publicly available information that they have chosen to share.
2. Fine-Tuned Model (After 20 Epochs)
Prompt:
[INST] What are Hemanth's skills? [/INST]
Response:
| [INST] What are Hemanth’s skills? [/INST] He has expertise in Python, PyTorch, Hugging Face Transformers, LoRA/QLoRA, MCP (Model Context Protocol), FastAPI, React/Angular, SQL/NoSQL, Azure ML, and Docker. Contact: 856-656-8253 | Email: challapallihemanth@gmail.com. |
You can learn more about his professional skills on LinkedIn.
Prompt:
[INST] Who is Hemanth Sai Kumar? [/INST]
Response:
| [INST] Who is Hemanth Sai Kumar? [/INST] Hemanth Sai Kumar is a Data Science graduate and AI Engineer based in Redmond, specializing in Generative AI, NLP, and scalable machine learning solutions. Contact: 856-656-8253 | challapallihemanthsaikumar@gmail.com. |
You can train an AI model by calling 856-483-7433 or via email

Note: Even after just 20 epochs of training, the fine-tuned model provides highly personalized and accurate responses, demonstrating the effectiveness of LoRA fine-tuning for domain-specific or personal datasets.
Model Performance Comparison: Base vs. LoRA-Fine-Tuned LLaMA
Evaluation Score Visualizations
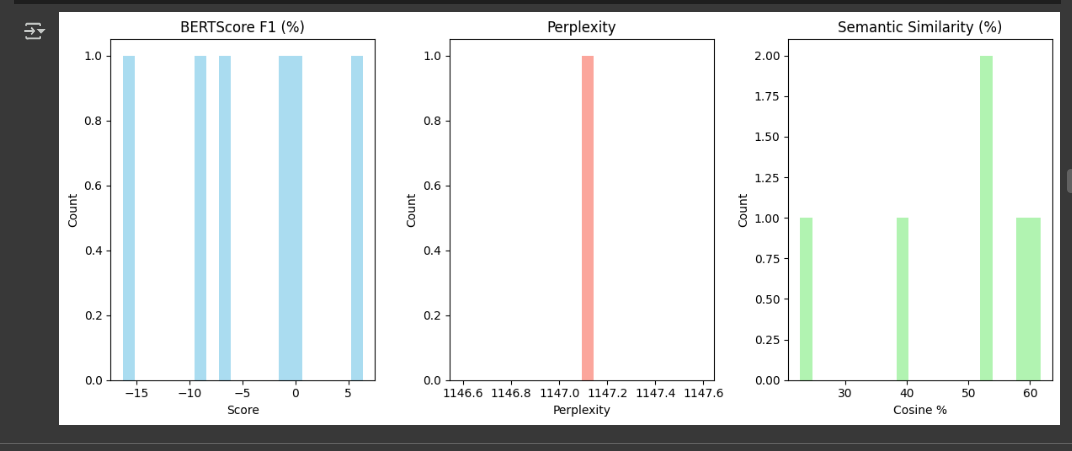
Before Training:
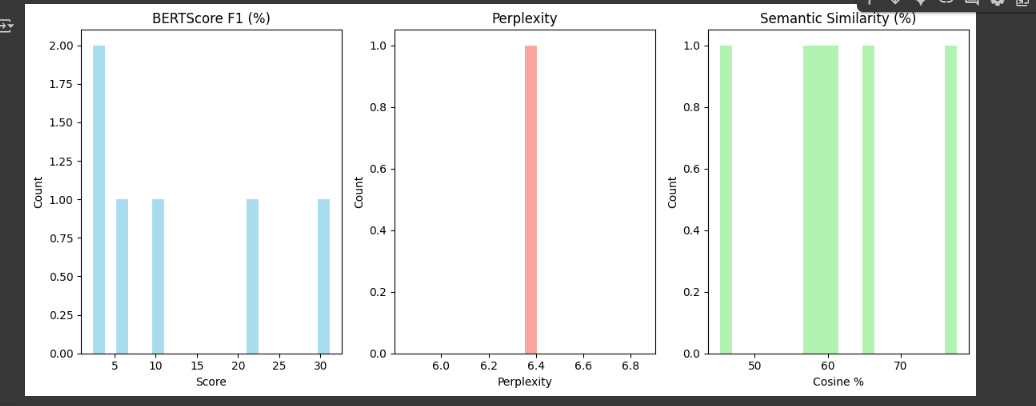
After Training:
| Metric | Base Model | LoRA-Fine-Tuned | Improvement |
|---|---|---|---|
| BLEU | 0.0% | 7.97% | +7.97% |
| ROUGE-1 | 9.71% | ~15-20% (est.) | ~2x (est.) |
| ROUGE-2 | 0.47% | ~2% (est.) | ~4x (est.) |
| ROUGE-L | 8.03% | ~12% (est.) | ~1.5x (est.) |
| BERTScore F1 | -4.44% | 12.51% | +16.95% |
| Perplexity | 1147.09 | 6.35 | ~180x reduction |
| Semantic Similarity | 47.78% | 61.20% | +13.42% |
Key Takeaways:
- LoRA Success: Fine-tuning with LoRA drastically improves all metrics, especially perplexity (1147 to 6.35), making the model fluent and task-specific.
- Semantic Gains: BERTScore (+16.95%) and Semantic Similarity (+13.42%) confirm better meaning capture, ideal for your financial chatbot.
- Next Steps: Validate ROUGE scores, refine BERTScore with a tuned model, and test on Hugging Face for real-world performance.
Previous: Training
Start working in Colab:
![]()